
Another look at the two-systems model of mindreading
Apperly and Butterfill (2009) and Butterfill and Apperly (2013) have proposed a two-systems model of mindreading. According to this model, humans make use of two distinct psychological systems in mindreading tasks. The model rests on three related claims. First of all, the early-developing system, which is taken to be efficient, fast and inflexible, is supposed to explain the positive findings based on spontaneous-response tasks showing that infants can track the contents of others’ false beliefs. The later-developing system, which is taken to be slower, inefficient and flexible, is supposed to be necessary for success at elicited-response false-belief tasks, which most children pass only when they are at least 4,5 years of age. Secondly, the two separate systems are supposed to co-exist in human adults. Finally, there are signature limits of the early-developing system: in particular, only the later-developing system is taken to enable someone to represent the content of another’s false belief about object identity.
Low and Watts, in a 2013 paper, took seriously the prediction of the two-systems model that representing the content of an agent’s false belief about object identity falls beyond the scope of the early-developing mindreading system and can only be executed by the later-developing system. They designed a task whose purpose was to probe participants’ understanding of the content of a male agent’s false belief about the identity of a two-colored puppet, using two different measures. I previously argued that the findings reported by Low and Watts (2013) fail to support the two-systems model of mindreading because it does not merely test participants’ ability to track the content of an agent’s false belief about an object’s identity but also their ability to revise or update their own belief about the puppet’s colors. Gergo Csibra has further suggested a follow-up experiment.So far as I know, Csibra’s suggestion has yet to be tested. On the other hand, Low, Drummond, Walmsley and Wang (2014) have designed a new quite interesting visual perspective-taking task, whose complexity matches that of Low and Watts’s (2013) earlier Identity task. Here I want to discuss this work and its implications.
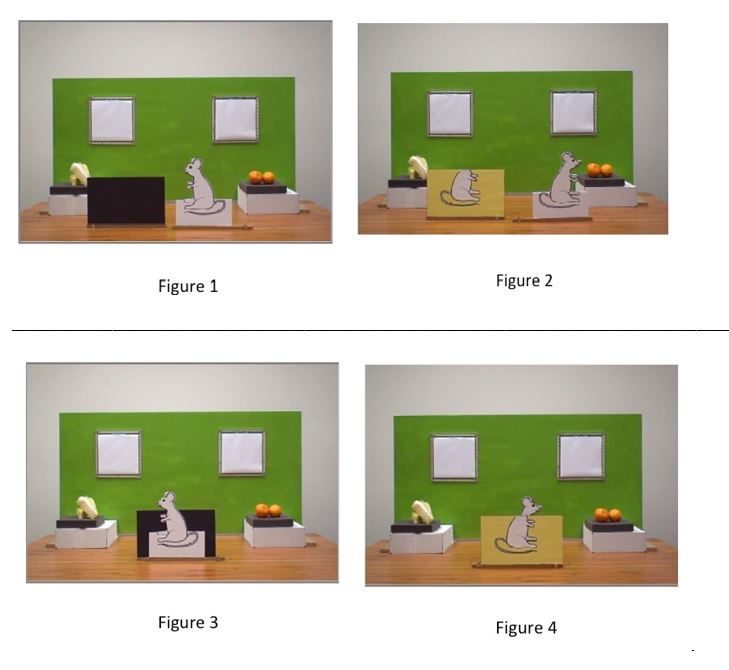
At the beginning of the familiarization condition of this new experiment, participants are first shown two displays lying on a table, in front of a green screen with two windows: a black cardboard panel and the cutout of a white mouse. On the table at the bottom of the window on the left, there is a piece of cheese, and at the bottom of the window on the right, there is a pair of oranges (Fig. 1). Both displays are rotated so that participants can see what is on the other side: on the other side of the cutout of the white mouse is the other profile of the white mouse; but on the other side of the black cardboard is a picture of the body of a head-less white mouse against a yellow background (Fig. 2). Next, the two matched pictures are rotated and participants now see the full right profile of a white mouse against a black background (Fig 3). Thirdly, after the two matched pictures have been rotated, they see the picture of a full white mouse against a yellow background (Fig. 4). Finally, while participants see the picture of the left profile of the white mouse against the black background, they also see the following sequence of events: (i) an agent appears behind and above the green screen with the two windows; (ii) a pair of visual and auditory stimuli serves as cues that the agent is about to perform an action; (iii) the agent reaches for the piece of cheese through the window on the left and pretends to feed the picture of the white mouse against the black background turned to the left side of the stage (Fig. 5).

In a nutshell, while they see the agent pretend to feed the picture of the left profile of the white mouse against the black background, participants have been made aware that the agent must be simultaneously taking himself to see the right profile of a full white mouse against a yellow background, while what he is really seeing is the result of applying the picture of the head-less mouse against the yellow background onto the picture of the full white mouse in its right profile.

In the belief induction trial, the picture of the full white mouse on both sides is replaced by a picture of a white rabbit (Fig 6i) and the display with a black cardboard on one side and a picture of a head-less white mouse against a yellow background on the other side is replaced by a picture of the left profile of a head-less white duck on a yellow background (Fig. 6ii). Everything else is the same except that the piece of cheese has been replaced by a piece of bread and the pair of oranges have been replaced by a pair of carrots (Fig. 6). Participants are made aware that when the two displays are matched onto each other, on one side, they see a picture of the left profile of the white rabbit against a black background (Fig. 7).

But on the other side, as a result of a perceptual Gestalt switch restricted to the shape of the head alone, the right profile of the rabbit’s head can be seen as the left profile of a duck’s head and participants can then see a full picture of the left profile of a white duck against a yellow background (Fig. 8). Finally, while participants see the picture of the left profile of the white rabbit against the black background with its head oriented towards the bread on the left, they see a new version of the same sequence of events as in the familiarization trial: (i) they see the agent appear again behind and above the green screen with the two windows (Fig. 9i); (ii) they see the pair of cues indicating that the agent is about to act (Fig 9ii); (iii) because they saw the agent feed the animal in front of him in the familiarization trial, they now expect him to do so again (Fig. 9iii).

If the agent’s goal is to feed the animal in front of him, then he has a choice: he can either reach for the bread through the left window or for the carrots through the right window. Which food the agent will select depends on which animal he believes is in front of him. As the participants’ task is to predict the agent’s choice, they must be able to represent the agent’s false belief that the animal in front of him is a duck, while participants see a rabbit. In order to represent the full content of the agent’s false belief, participants must remember that what they are seeing is an ambiguous picture. They must further remember that, unbeknownst to the agent, what he is seeing is a picture of a duck made up of two separate pieces: the picture of a head-less body of a duck and the picture of a head that can be seen as either the head of a rabbit or the head of a duck (Fig. 8).
Following Low and Watts (2013), Low and colleagues (2014) tested three populations of participants (3-year-olds, 4-year-olds and adults) and probed their ability to track the content of the agent’s false belief about the identity of the ambiguous picture, using two different measures: in the anticipatory looking condition, they coded participants’ first gaze on the location of the relevant food item 1,750-ms after the cues. In the elicited-response condition, participants were asked: “Which food will the man reach for to feed the animal?” (I will restrict myself to the adults’ results.)
Low and colleagues found that only 37% of the adult participants correctly first gazed at the bread and that 56% gave correct answers to the prediction question while failing to first gaze at the bread. Low and colleagues argue that their findings again corroborate the two-systems model on the ground that the early-developing system that guides anticipatory looking was defeated by the task of representing the content of the agent’s false belief about the identity of the ambiguous picture, which only the later-developing system, which guides adults’ responses to prediction questions, can achieve.
Low and Watts’s (2013) earlier experiment failed to support the two-systems model because it did not test the ability to track the content of another’s false belief about an object’s identity alone; it also tested one’s ability to update one’s own belief about the object’s colors. My main criticism of the new experiment by Low and colleagues is that it fails to support the two-systems model for a related but different reason. Low and colleagues assume that while the response to the explicit prediction question is guided by the later-developing flexible and inefficient system, the first gaze in the anticipatory looking condition is guided by the earlier-developing efficient and inflexible system. But in fact, the elicited-response condition and the anticipatory condition do not make the same executive demands at all.
In the elicited-response condition, participants are asked the question: “Which food will the man reach for to feed the animal?” In order to correctly predict that the agent will select the bread, it is sufficient to (i) represent the fact that the agent is seeing a duck (while participants see a rabbit) and (ii) to retrieve from long-term memory the association between ducks and bread. Participants can solve the task without keeping track of the respective locations of the bread and the carrots.
But of course they must monitor the respective locations of the bread and the carrots in the anticipatory looking condition. In this condition, participants must gaze at the location of the bread on their own left. It may seem as if this visual task should be easier than the response to the explicit question. But it is not, for two concurring reasons. In order to gaze at the location of the bread on their left, participants must resolve two spatial puzzles.
First of all, if they visualize the content of the agent’s visual experience of a duck, then they must become aware that, while they see the rabbit’s face and mouth turned to the bread on their left, the agent is seeing the duck’s face and mouth turned towards the carrot on their right (Fig. 9). If so, then they must inhibit the spatial congruence between the carrots and the orientation of the duck’s head and mouth, as they visualize it.
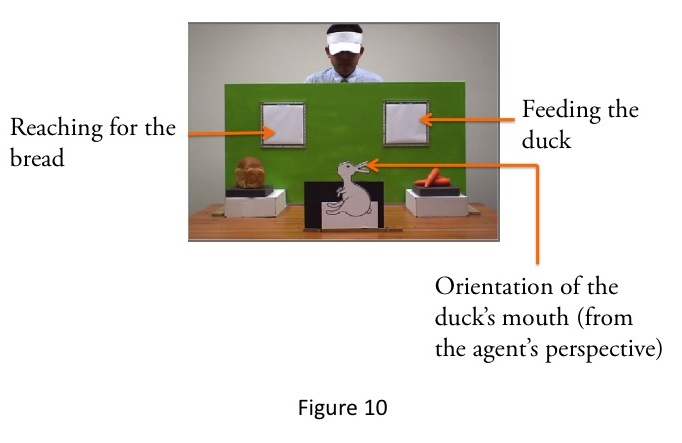
Secondly, from a visuomotor point of view, the agent’s action of reaching for the bread and feeding the duck raises a special spatial puzzle: the agent cannot use the same hand both for reaching for the bread and for feeding the duck. The agent can only reach for the bread through the left window with his right arm and hand (Fig. 9). But as the duck’s mouth is turned towards the window above the carrots on the right, the agent will only be able to feed the duck through the right window. In order to do so, he must transfer the bread from his right hand to his left hand (Fig. 10). Consequently, the action of reaching for the bread and feeding the duck is likely to be an inefficient and lengthy process.
The fact that adult participants are worse in the anticipatory looking than in the elicited-response condition could only support the two-systems model if the executive resources required in both conditions were equal. But as I have argued, the executive demands made by the anticipatory looking condition may be more overwhelming than the executive demands made by the elicited-response condition and participants’ response in the former condition are tested only 1,750-ms after the cues, while there is no time limit imposed in the elicited-response condition.
References
Csibra, G. (2012) Revising the belief revision paradigm.
Jacob, P. (2012) Do we use different tools to mindread a defendant and a goalkeeper?
Low, J., & Watts, J. (2013) Attributing false beliefs about object identity reveals a signature blind spot in humans’ efficient mind-reading system. Psychological Science, 24, 305–311. doi:10.1177/0956797612451469
Low, J. Drummond, W., Walmsley, A. and Wang, B. (2014) Representing how rabbits Quack and competitors act: limits on preschoolers’ efficient ability to track perspective. Child Development, 85, 1519-1534.