
Does replication matter? The case for conceptual replication and strong inference
Recent findings from a massive collaborative project (OSF, 2015), attempting to replicate many of the findings published in top psychology journals, have suggested that roughly half of these fail to replicate. These findings deservedly made headlines, and have generated a great deal of reaction amongst psychologists. While some have argued that the estimated rate of non-replicability may have been overestimated (Gilbert, King, Pettigrew, & Wilson, 2016), in water cooler conversations a far more skeptical viewpoint about the usefulness of studying replicability at all has begun to emerge.
To summarize, the skeptics hold that we shouldn’t care so much about whether any individual study replicates; what we should instead care about are whether the theories they were meant to investigate are true. Non-replications don’t tell us much if anything about the theories we ultimately care about.
This view goes overboard because at the end of the day, experiments are data points that help paint a theoretical picture. If there are 100 published studies pointing to the existence of automatic priming effects (e.g. reading a cross-word about ageing makes people walk slower), and there is no systematic bias in the published articles, then this is a pretty good reason to believe in automatic priming effects. If however we randomly pick 10 of those to replicate, and 9 fail, this will justifiably undermine our confidence in the underlying theory.
With that being said, the critics of the obsession with replicability also have a point. As scientists, we should care more about theories than about individual findings. There is far too much emphasis on how individual findings might have been produced by various forms of bias or experimental malpractice, and not nearly enough clear thinking about how experimental evidence should be translated into beliefs about how the mind works.
The computer scientist Chris Drummond (2009) has made a distinction between “replicability” and “reproducibility” that I think is very useful. A “replication” in Drummond’s terminology is the production of a nearly identical set of results in a nearly identical experimental setting to a previously run experiment. So this would involve running the replication attempt with the same stimulus set, from the same pool of participants, with the same instructions, same experimental protocol, etc. On the other hand, a reproduction would be the production of a set of results which is qualitatively similar to the original set, but in an experimental context where the precise experimental parameters may have changed slightly or even dramatically. “Qualitatively similar” here can be fairly precisely defined to refer to parameter settings likely to produce effects in the reproduction which are predicted by the theory thought to explain the original results.
One can think about differences in parameter settings between two experiments as being plotted on a similarity scale (see Figure 1A below). Imagine that all experiments which can be plotted on the scale are capable of testing all theories that could potentially explain the originally observed effect. If a new experiment is very close to the point of reference on the scale, then we should be more likely to call that a replication attempt. The further away it is, the more likely we should be to call it a reproduction attempt. Following popular terminology from social psychology, we could also call this an attempt at a “conceptual replication” (Stroebe & Strack, 2014).
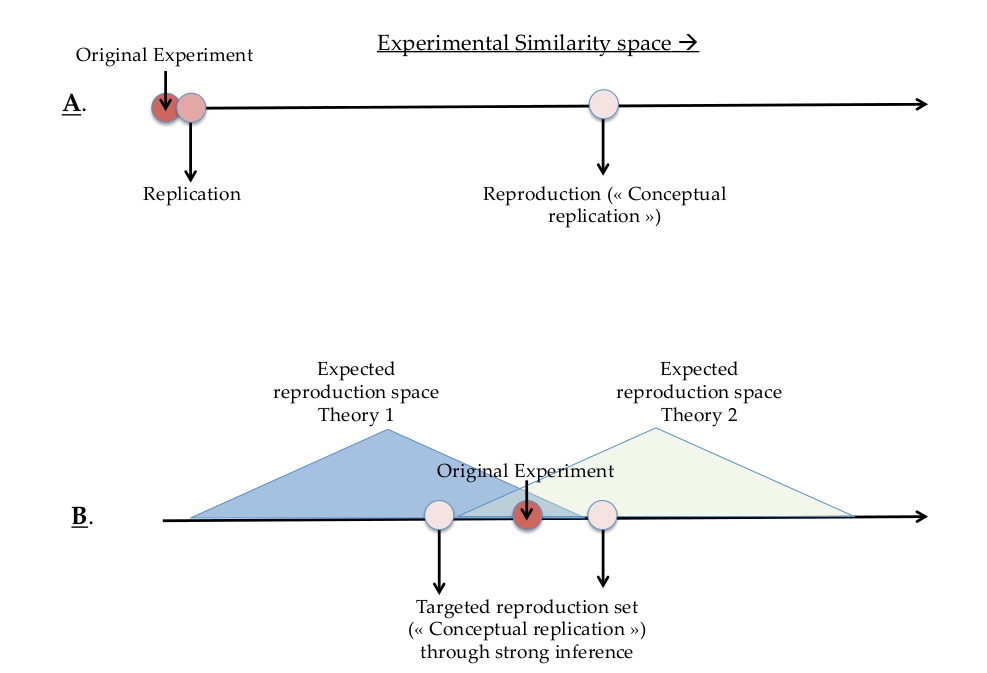 Figure 1: (A) “Replications” in Drummond’s sense are the production of the same set of results to those observed in an original experiment. The replication attempt involves nearly identical experimental settings to those employed in the original experiment. We say “nearly” here because no two sequentially run experiments run can ever be perfectly identical given that they are run at different times. “Reproductions” (also known as “conceptual replications”) provide evidence for the mechanism postulated to explain the originally observed effect but in a very different experimental setting. (B) The method of “strong inference” involves targeted reproductions in specifically those experimental parameter settings that can help us discriminate between competing theories.
Figure 1: (A) “Replications” in Drummond’s sense are the production of the same set of results to those observed in an original experiment. The replication attempt involves nearly identical experimental settings to those employed in the original experiment. We say “nearly” here because no two sequentially run experiments run can ever be perfectly identical given that they are run at different times. “Reproductions” (also known as “conceptual replications”) provide evidence for the mechanism postulated to explain the originally observed effect but in a very different experimental setting. (B) The method of “strong inference” involves targeted reproductions in specifically those experimental parameter settings that can help us discriminate between competing theories.
Talking about things in this way can help us think more clearly about various forms of theoretical biases and malpractice that may occur in psychological science. To illustrate this, consider the following hypothetical scenario. Researchers are interested in testing whether adults reading text written in difficult fonts (the disfluent condition) will learn more than adults reading text in easy to read fonts (the fluent condition), or vice-versa. They start out with the counterintuitive hypothesis that disfluency will improve learning.
Now (as is more and more common), imagine also that this experiment can be run on Amazon’s Mechanical Turk, which is an on-line platform allowing for quick and cheap data collection. In advance, the researcher identifies 10 difficult to read text fonts, and 10 easy to read text fonts. The researcher is technologically savvy, and figures out a way to automate internet-based data collection. They end up running 100 different experiments, one experiment for each possible combination of easy and difficult fonts. Each experiment thus compares one easy to read text font with one hard to read text font. Of all these experiments, only one yields the desired significant difference whereby the hard to read font produces higher levels of learning. The experimenter, having read all about the replicability problem, wants to make sure their experiment is replicable. So they replicate the one experiment that worked, not once but twice. Then they go on to publish these findings, and conclude in the paper that font difficulty has a general influence on learnability.
Clearly something has gone wrong here, but the problem has nothing to do with replicability since the original results fully replicate. The problem is reproducibility. What has actually happened is that the researcher has oversampled the experimental parameter space, and has chosen to focus only on the very specific parameters where the experiment replicates while neglecting those parameters that yield theoretically inconvenient results. This produces a bias not at the level of the individual published results, but at the level of the theory that is being drawn from the results. By ignoring the theoretically inconvenient findings, the researcher is negligently leading us to draw a general conclusion about the influence of fonts on learnability that is, in this case, highly unlikely to be true.
My experience is that something approximating this is not entirely uncommon in psychology, though experimenters might run, say, 5 versions of an experiment before finding one that works instead of the 100 illustrated here. Experimental settings that produce theoretically inconvenient results are sometimes dismissed, and this can be justified with post-hoc reasoning. “These fonts weren’t fair tests of the hypothesis after all” because one was too easy or too hard, or too familiar, or too large, etc… “My-side” bias, which is defined as the tendency to seek out information which supports one’s pre-existing beliefs or desires while ignoring or discounting valid contradictory evidence, has been argued to influence the quality, and likely replicability, of individual findings (e.g. Papp, 2014; Nuzzo, 2015). What the above case illustrates is that the same type of bias can operate at the level of theoretical inference.
Of course, not all cases of non-reproducibility are due to scientific malpractice or bias, just as not all cases of non-replicability are. In some instances, a researcher draws a perfectly reasonable conclusion about a pattern of data that just happens to be wrong. There are also cases in which it really is the case that the experimental parameter settings do not offer the possibility of a fair test of the hypothesis. For example, imagine that there actually is a general effect of font difficulty on learning. But also imagine that the material the participant is being asked to learn is extraordinarily difficult, say a series of 20 digit numbers. In a case like this, any true effect that exists will be masked because the task actually is too difficult. In both the fluent and disfluent condition, participants would be at 0% accuracy because the task is just too hard. However if thhe experiment had involved a series of 4 or 5 digit numbers, then the experiment might have worked.
What is needed are theories of (1) underlying mental processes of interest and (2) task performance that are capable, at least in principle, of making clear predictions about the range of parameter settings over which a previously observed effect should reproduce. Thinking about things in this way helps highlight the impact of “strong inference,” (Platt, 1964) which is a de-biasing technique that I think is under appreciated in everyday practice. The idea of strong inference is that researchers should not, as is too often the case, simply be content with having a theory and finding a few significant results that were predicted by that theory. Instead, the researchers should force themselves to articulate one or multiple alternative hypotheses. In conjunction with a theory of task performance, one can then identify experimental parameters where the various theories make competing predictions, and focus in on those (schematically depicted in Figure 1B).
This method, which has been widely adopted in biology since the 60’s with great success (Fudge, 2014), forces scientists to explore the experimental parameter space by selectively focusing in on series of targeted sets of reproductions that can advance theory. In doing so, one would likely avoid the type of bias described in the hypothetical disfluency situation above. For example, if a researcher (by chance or unconscious malpractice) found a significant boost in learning for disfluent fonts, they might then articulate two competing theories which could explain the effect. Theory 1 may be that disfluent fonts improve learning because specific types of letter shapes require more attention to process. Increased attention “spills over” onto the learning task. Theory 2 may be that disfluent fonts improve learning not because of the shapes of individual letters, but because disfluent fonts involve hard to process holistic word forms (which in turn increase attention and improve learning). The researchers would then devise a minimally contrasting set of reproduction attempts which could differentiate between the two alternative hypotheses. In doing so, they would quickly realize that the original effect fails to extend in any of the expected directions, and that there may therefore be doubts about the original interpretation of the results.
The emphasis of this view is somewhat different from those who argue that concentration on direct replications is the primary way forward for psychological science (e.g. Simmons, 2014; Chambers, 2012). Many who hold this view dismiss “conceptual replications” (i.e. “reproduction attempts” in Drummond’s terminology) as being overly limited in the type of information they provide. But I think there is a larger point here that is not being expressed. Yes, direct replication is important because we want to know that individual data points are reliable. But if you are interested in theoretical progress via experimentation, targeted conceptual replication is also required.
References
Chambers, C. (2012). You can’t replicate a concept.
Drummond, C. (2009) .Replicability is not reproducibility: nor is it good science. Proceedings of the Evaluation Methods for Machine Learning Workshop 26th International Conference for Machine Learning, Montreal, Quebec, Canada.
Fudge, D. S. (2014). Fifty years of JR Platt's strong inference. Journal of Experimental Biology, 217(8), 1202-1204.
Gilbert, D. T., King, G., Pettigrew, S., & Wilson, T. D. (2016). Comment on "Estimating the reproducibility of psychological science." Science, 351, 1037-a-1038-a.
Open Science Collaboration. (2015). Estimating the reproducibility of psychological science. Science, 349(6251), aac4716.
Paap, K. R. (2014). The role of componential analysis, categorical hypothesising, replicability and confirmation bias in testing for bilingual advantages in executive functioning. Journal of Cognitive Psychology, 26, 242–255.
Platt, J. R. (1964). Strong Inference. Science, 146, 347–353.
Simons, D. J. (2014). The value of direct replication. Perspectives on Psychological Science, 9(1), 76-80.
Stroebe, W., & Strack, F. (2014). The alleged crisis and the illusion of exact replication. Perspectives on Psychological Science, 9, 59–71.