Do we use different tools to mindread a defendant and a goalkeeper?
Previously on cognitionandculture — Last year, Pierre Jacob posted a critical review of the so-called two-systems model of mindreading, according to which humans use two distinct mental tools to understand the thoughts of others: one is fast and automatic, the other is slower, more reflective, and based on less immediate cues. This is a follow-up on his earlier post.
In a pair of experiments reported in a paper to appear shortly in Psychological Science, Jason Low and Joseph Watts used two distinct paradigms to investigate the human ability of 3-year-olds, 4-year-olds and adults to ascribe false beliefs to an agent. They take their findings to support the two-systems model of mindreading. On this model, while an efficient and inflexible system (system 1) enables a soccer player to score a goal by deceiving the goalkeeper in a split-second, a flexible but inefficient system (system 2) underlies a judge’s reflection over a defendant’s motivations and epistemic states over several days.
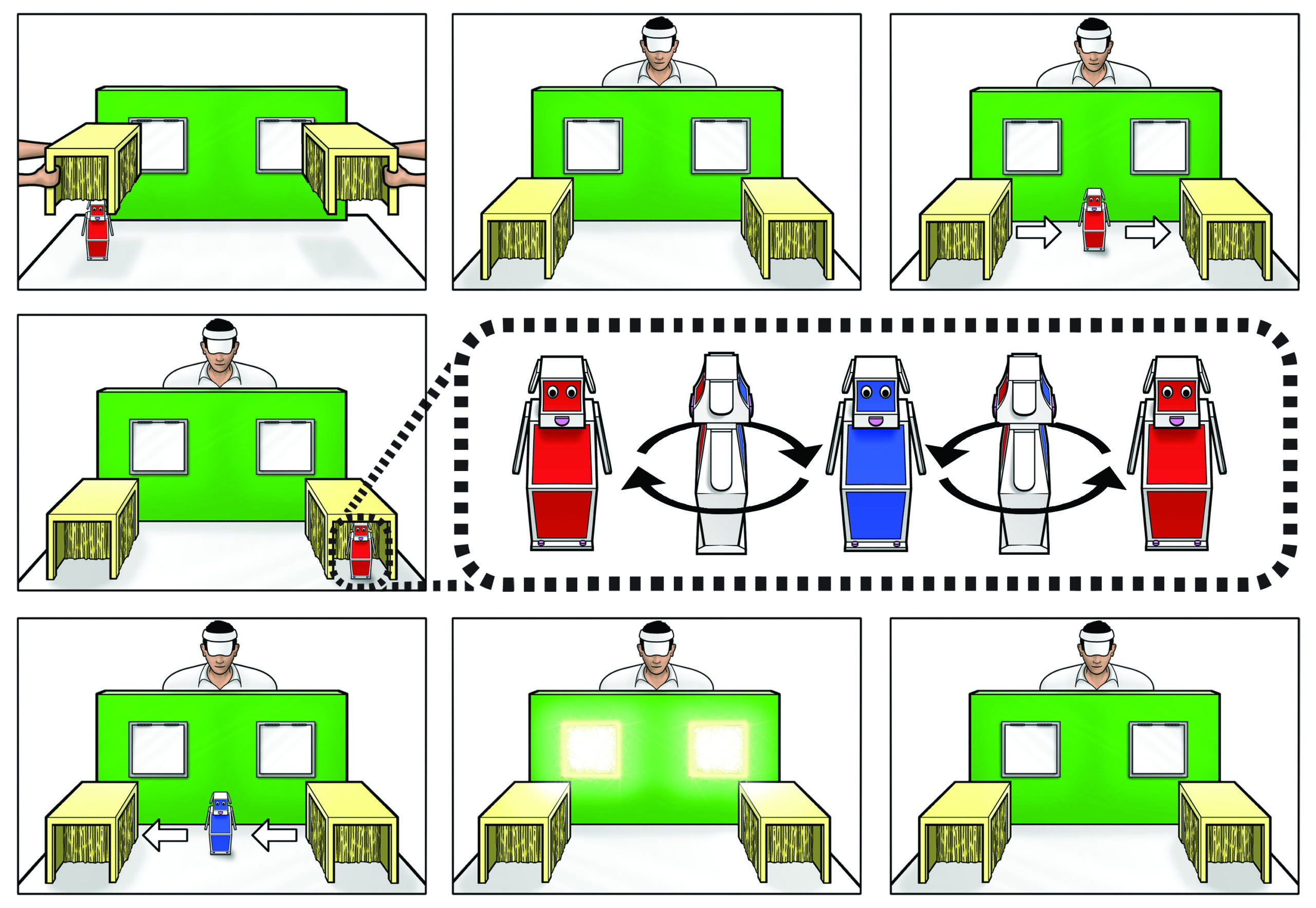 Low and Watts’ identity task: Only the participant, not the agent, knows that the puppet that first moves into the right box and then into the left box is blue on one side and red on the other side. Which of the two boxes will the agent, who prefers blue over red things, look into?
Low and Watts’ identity task: Only the participant, not the agent, knows that the puppet that first moves into the right box and then into the left box is blue on one side and red on the other side. Which of the two boxes will the agent, who prefers blue over red things, look into?
Location and identity
While advocates of the two-systems model have argued that system 1 can only represent an agent’s registration of the presence of an object at a location, they have further argued that one of the hallmarks of system 2 is the ability to reason about beliefs about an object’s identity. For example, only system 2 is taken to enable me to understand that if Carla fails to know that Cicero was called not only ‘Cicero’ but also ‘Tully’, then she might endorse the belief that Cicero was a Roman orator only when this belief is expressed using the name ‘Cicero’, but not the name ‘Tully’, to refer to Cicero.
Using a classical location task (modeled on the classic Ann-Sally task), Low and Watts confirm earlier findings that 3-year-olds, who know the location of an object, find it very hard to correctly answer the question: “Where will an agent with a false belief about its location look for the object?” They also confirm earlier findings that the same children spontaneously look at the box which the agent falsely believes to contain the object showing thereby that they correctly anticipate the agent’s action by gazing at the right box, while they fail the verbal task.
In Low and Watts’ identity task (cf. figure), participants are first given evidence that the agent has a preference for blue over red objects. Secondly, they are requested to understand that the agent, who only sees the blue side of a puppet that is blue on one side and red on the other side, must believe that the puppet is blue all over (so long as the agent has not seen the puppet’s red side). Thirdly, they are further requested to understand that after the agent saw the puppet enter an opaque box on his right under its blue side, later emerge from the box under its red side and finally enter a box on his left, the agent must falsely believe that there are two distinct puppets, the blue one still in the box on his right, and the red one in the box on his left. In this task, however (as the middle line of the figure makes clear), only participants, not the agent, are made aware that there is only one puppet which is blue on one side and red on the other side. Consequently, only participants know that the unique puppet ends up being in the box on the agent’s left (as made clear by the lower line of the figure). Low and Watts also tested participants’ understanding of the agent’s false belief that the blue puppet is in the right box on the basis of either their anticipatory gaze at the box on the right or their explicit answer to the question: “Which box will the agent look into?”
Low and Watts report accurate anticipatory looking by almost all 3-year-olds, 4-year-olds and adults tested in the location task, but by very few among the 3- and 4-year-olds and only by 25% of the adults, in the identity task. Furthermore, while in the identity task, most of the 3-year-olds also failed to answer the prediction question about the action of the agent with a false belief about identity (i.e. in which of the two boxes will the agent look for the blue puppet?), 70% of the adults and 50% of the 4-year-olds, who failed to show accurate anticipatory looking, were able to answer the prediction question in the identity task.
First, Low and Watts assume that system 1 enabled all participants to show accurate anticipatory looking in the location task, but not in the identity task, nor to answer the prediction question in the location task.
Secondly, they assume that system 2 enabled adults and to some extent 4-year-olds, but not 3-year-olds, to answer the prediction question in both the location and the identity tasks. Thus, Low and Watts found that 70% of adults correctly answered the prediction question, but failed to show anticipatory looking, in the identity task.
Does this interesting finding support the view that understanding the propositional contents of another’s belief about identity is a signature of the limitations of system 1 and a hallmark of system 2? Close inspection of the structure of their identity task suggests a different interpretation.
In the familiarization trials, participants learn that the agent has a preference for blue over red objects. In the first stage of the belief-induction trial, after seeing the agent watch what appears to them to be a red puppet move from a left to a right box, participants ascribe to the agent the belief that the red puppet is now in the right box. But as a result of the familiarization trials, they should not think it particularly relevant for the agent to track the location of the red puppet, since in the familiarization trials the agent showed that he had a preference for blue over red objects.
In the second (belief-revision) stage, after participants, but not the agent, learn that the puppet is in fact red on one side and blue on the other side, they revise their own belief about the color of the puppet. As a result, they also revise the content of their earlier belief-ascription and motivations to the agent: now they take the agent to believe that what is in the right box is a blue, not a red, puppet, and therefore a desirable object.
In the third stage, after watching the agent see the puppet, which looks blue to them, move from the right to the left box, they can ascribe to the agent (who fails to know the true colors of the puppet) the following false beliefs: (i) there are two puppets; (ii) the blue desirable one is in the right box; (iii) the red one is in the left box.
Two points are worth making. First, in order to ascribe to the agent the relevant false belief (ii) that the blue puppet is in the right box, participants must understand that the agent’s perspective on the puppet is different from their own. But that is not sufficient: in the second (belief-revision) stage of the belief-induction trial, participants must further revise their own belief about the color of the robot-dog and also compute the consequences of this belief revision on the revision of the contents of the beliefs and motivations ascribed to the agent. Belief revision, not representing the content of another’s belief about an object’s identity per se, might explain why adults failed to show anticipatory looking.
Secondly, participants could not accurately anticipate the agent’s action by looking at the right box unless they had ascribed to the agent the false belief that what he takes to be a blue puppet is in the right box, which requires participants to revise their own belief. But while Low and Watts did not impose any time limit for answering the prediction question, they measured anticipatory looking only 1,750 ms after the end of the third stage of the belief-induction trial. This temporal difference alone might explain why adults could answer the prediction question, but did not show accurate anticipatory looking, in the identity task.
Comments Disabled